Category NoSQL

Watch Davy Suvee present at GraphConnect London 2013 on the power of graph databases to analyse biological datasets. The Power of Graphs to Analyze Biological Data – Davy Suvee @ GraphConnect London 2013 from Neo Technology on Vimeo.

A few months ago, I discovered Vertica’s “Counting Triangles”-article through Prismatic. The blog post describes a number of benchmarks on counting triangles in large networks. A triangle is detected whenever a vertex has two adjacent vertices that are also adjacent to each other. Imagine your social network; if two of your friends are also friends
Today, Datablend announces Similr to be available for beta sign-up. Similr allows scientist (both from academics and enterprise) to quickly search for compounds that exhibit a particular chemical structure. It employs a wide range of fingerprinting algorithms, which combined, allow to identify matching compounds in millisecond time. Similr’s functionalities are available through a flexible and
Recently, I’ve started implementing a number of Redis-based solutions for a Datablend customer. Redis is frequently referred to as the Swiss Army Knife of NoSQL databases and rightfully deserves that title. At its core, it is an in-memory key-value datastore. Values that are assigned to keys can be ‘structured’ through the use of strings, hashes,
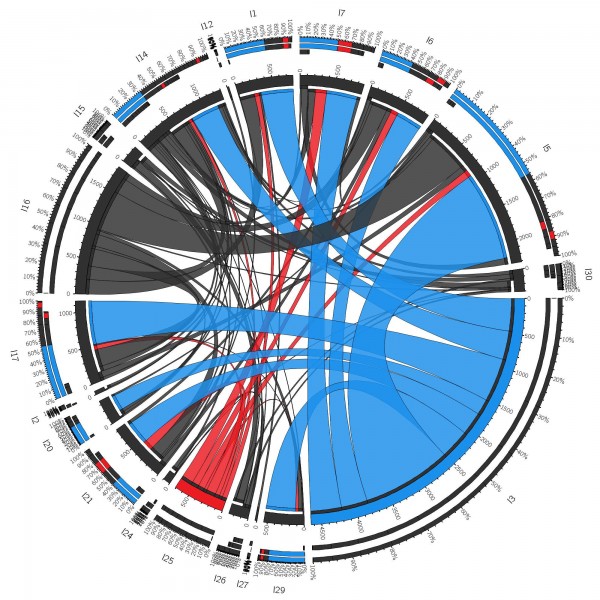
Storing massive amounts of data in a NoSQL data store is just one side of the Big Data equation. Being able to visualize your data in such a way that you can easily gain deeper insights, is where things really start to get interesting. Lately, I’ve been exploring various options for visualizing (directed) graphs, including

[information] Part 1 of this article describes the use of MongoDB to implement the computation of molecular similarities. Part 2 discusses the refactoring of this solution by making use of MongoDB’s build-in map-reduce functionality to improve overall performance. Part 3 finally, illustrates the use of the new MongoDB Aggregation Framework, which boosts performance beyond the
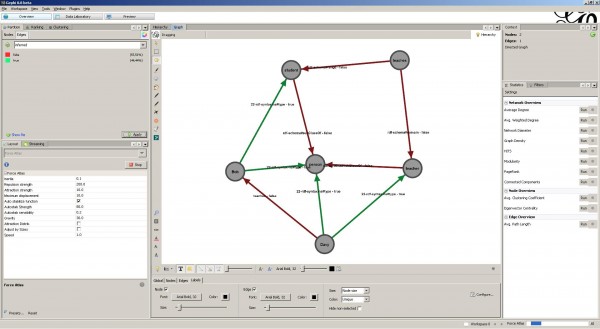
Last week, the Neo4J plugin for Gephi was released. Gephi is an open-source visualization and manipulation tool that allows users to interactively browse and explore graphs. The graphs themselves can be loaded through a variety of file formats. Thanks to Martin Škurla, it is now possible to load and lazily explore graphs that are stored

NoSQL seems to be ready for prime time. Several NoSQL companies, including 10gen (MongoDB), DataStax (Cassandra) and Neo Technology (Neo4J), recently received millions in funding to expand their (commercial) NoSQL offerings. Even Oracle is now entering the already crowded NoSQL-space with its very own key-value NoSQL Database 11g. No doubt that this type of publicity
[information] Part 1 of this article describes the use of MongoDB to implement the computation of molecular similarities. Part 2 discusses the refactoring of this solution by making use of MongoDB’s build-in map-reduce functionality to improve overall performance. [/information] In part 1 of this article, I described the use of MongoDB to solve a specific
[information] Part 1 of this article describes the use of MongoDB to implement the computation of molecular similarities. Part 2 discusses the refactoring of this solution by making use of MongoDB’s build-in map-reduce functionality to improve overall performance. [/information] In one of my previous blog posts, I debated the superficial idea that you should own