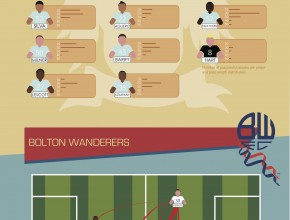
The power of Manchester City: a data analysis
What makes Manchester City such a great team? The infographic below illustrates one of the teams most powerful characteristics: its successful passing capability. The visualisation is based upon the Opta dataset released in August 2011, containing the high detailed Bolton vs Manchester City match statistics. The data has been loaded in the neo4j graph databases
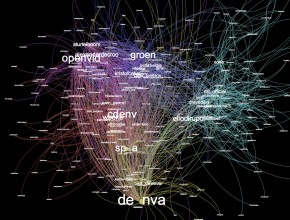
Coalition-Cocktail – Hacking the Elections @ Engagor
Last weekend, Engagor organised their hacktheelections hackaton. The Datablend team (Quentin, Stijn and Davy) was joined by Marc Broos, Tim Coene and Josbert van de Zande with one goal in mind: trying to visualise the (pre-arranged?) political coalition and, if possible, also predict the formation-period. Technically, we extracted over 160K tweets through the Engagor API.

Datablend lanceert vk14-bingo.be
Wordt U ook overladen met informatie in verband met de komende verkiezingen? Bent U, net zoals zo vele andere burgers, op zoek naar een eenvoudig alternatief waarbij U in 1 oogopslag kunt zien waar elke partij voor staat? Zoek niet langer en maak gebruik van vk14-bingo.be. We hebben voor U de verschillende partijprogramma’s woord voor

The power of graphs to analyse biological data
Watch Davy Suvee present at GraphConnect London 2013 on the power of graph databases to analyse biological datasets. The Power of Graphs to Analyze Biological Data – Davy Suvee @ GraphConnect London 2013 from Neo Technology on Vimeo.
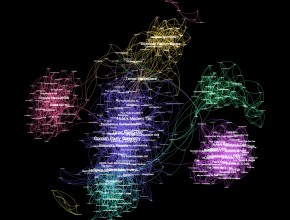
Yelp graph: checkin-based business clustering
Recently, Yelp made available a sample dataset from the greater Phoenix metropolitan area including around 11.000 business, 8000 checkin-sets, 43.000 users and 230.000 user reviews. With the help of this data, data scientists can execute real-life experiments with various data mining/machine learning algorithms. In our case, we are interested in finding out whether it is possible

Counting triangles smarter (or how to beat Big Data vendors at their own game)
A few months ago, I discovered Vertica’s “Counting Triangles”-article through Prismatic. The blog post describes a number of benchmarks on counting triangles in large networks. A triangle is detected whenever a vertex has two adjacent vertices that are also adjacent to each other. Imagine your social network; if two of your friends are also friends
Similr: blazingly fast chemical similarity searches
Today, Datablend announces Similr to be available for beta sign-up. Similr allows scientist (both from academics and enterprise) to quickly search for compounds that exhibit a particular chemical structure. It employs a wide range of fingerprinting algorithms, which combined, allow to identify matching compounds in millisecond time. Similr’s functionalities are available through a flexible and
Redis and Lua: a NoSQL power-horse
Recently, I’ve started implementing a number of Redis-based solutions for a Datablend customer. Redis is frequently referred to as the Swiss Army Knife of NoSQL databases and rightfully deserves that title. At its core, it is an in-memory key-value datastore. Values that are assigned to keys can be ‘structured’ through the use of strings, hashes,
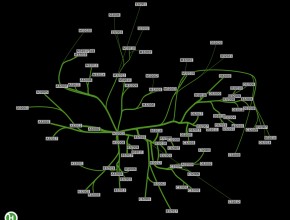
Hubway Data Visualization Challenge Entry: the flow of bikers
Last week, Hubway announced its Data Visualization Challenge. Hubway is a bike sharing system located in the Boston area: you simply pick up a bike at a particular station and drop it off at the closest station near your destination. For this challenge, Hubway released a CSV-file, containing over half a million rides. Each entry
Yesterday evening, the 9th BigData.be MeetUp was organised at the offices of NGDATA in Ghent. With 45 people showing up, this was our best attended MeetUp till know, illustrating the growing popularity of Big Data in Belgium. The meeting had a line-up of three presentations: Kenny Helsens, who presented a wrap-up of the zimmo.be project

Last week, Datablend open-sourced two new Tinkerpop Blueprints implementations: blueprints-mongodb-graph and blueprints-datomic-graph. Tinkerpop is an open source project that provides an entire stack of technologies within the Graph Database space. At the core of this stack is the Blueprints framework. Blueprints can be considered as the JDBC of Graph Databases. By providing a collection of

Back To The Future with Datomic
At the beginning of March, Rich Hickey and his team released Datomic. Datomic is a novel distributed database system designed to enable scalable, flexible and intelligent applications, running on next-generation cloud architectures. Its launch was surrounded with quite some buzz and skepticism, mainly related to its rather disruptive architectural proposal. Instead of trying to recapitulate
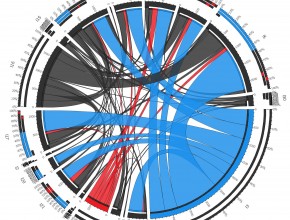
Circle through your Google Analytics data with Neo4J and Circos
Storing massive amounts of data in a NoSQL data store is just one side of the Big Data equation. Being able to visualize your data in such a way that you can easily gain deeper insights, is where things really start to get interesting. Lately, I’ve been exploring various options for visualizing (directed) graphs, including

The joy of algorithms and NoSQL revisited: the MongoDB Aggregation Framework
[information] Part 1 of this article describes the use of MongoDB to implement the computation of molecular similarities. Part 2 discusses the refactoring of this solution by making use of MongoDB’s build-in map-reduce functionality to improve overall performance. Part 3 finally, illustrates the use of the new MongoDB Aggregation Framework, which boosts performance beyond the
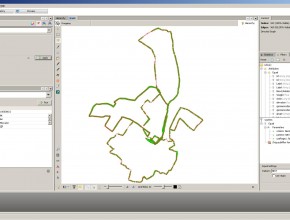
Running along the graph using Neo4J Spatial and Gephi
When I started running some years ago, I bought a Garmin Forerunner 405. It’s a nifty little device that tracks GPS coordinates while you are running. After a run, the device can be synchronized by uploading your data to the Garmin Connect website. Based upon the tracked time and GPS coordinates, the Garmin Connect website
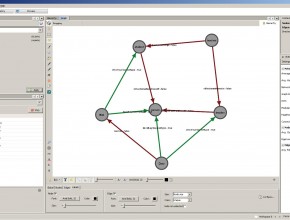
Visualizing RDF Schema inferencing through Neo4J, Tinkerpop, Sail and Gephi
Last week, the Neo4J plugin for Gephi was released. Gephi is an open-source visualization and manipulation tool that allows users to interactively browse and explore graphs. The graphs themselves can be loaded through a variety of file formats. Thanks to Martin Škurla, it is now possible to load and lazily explore graphs that are stored

The (non-)sense of NoSQL O(R)M frameworks
NoSQL seems to be ready for prime time. Several NoSQL companies, including 10gen (MongoDB), DataStax (Cassandra) and Neo Technology (Neo4J), recently received millions in funding to expand their (commercial) NoSQL offerings. Even Oracle is now entering the already crowded NoSQL-space with its very own key-value NoSQL Database 11g. No doubt that this type of publicity
The joy of algorithms and NoSQL: a MongoDB example (part 2)
[information] Part 1 of this article describes the use of MongoDB to implement the computation of molecular similarities. Part 2 discusses the refactoring of this solution by making use of MongoDB’s build-in map-reduce functionality to improve overall performance. [/information] In part 1 of this article, I described the use of MongoDB to solve a specific
The joy of algorithms and NoSQL: a MongoDB example (part 1)
[information] Part 1 of this article describes the use of MongoDB to implement the computation of molecular similarities. Part 2 discusses the refactoring of this solution by making use of MongoDB’s build-in map-reduce functionality to improve overall performance. [/information] In one of my previous blog posts, I debated the superficial idea that you should own

RDF data in Neo4J: the Tinkerpop story
[information] My previous blog post discussed the use of Neo4J as a RDF triple store. Michael Hunger however informed me that the neo-rdf-sail component is no longer under active development and advised me to have a look at Tinkerpop’s Sail implementation. [/information] As mentioned in my previous blog post, I recently got asked to implement

Storing and querying RDF data in Neo4J through Sail
[information] This blog post discusses the use of Neo4J as a RDF triple store. Michael Hunger however informed me that the neo-rdf-sail component is no longer under active development and advised me to have a look at Tinkerpop’s Sail implementation. Read the updated version of this article here. [/information] 1. Introduction Recently, I got asked

Should Big Data always be Big?
Yesterday evening the first BigData.be MeetUp was organized at the IBBT in Ghent. The intention of this meeting is to bring together Belgian Big Data and NoSQL enthusiasts. It’s an ideal opportunity to share thoughts and experiences with a mix of people, each having different backgrounds and levels of expertise with Big Data and NoSQL.
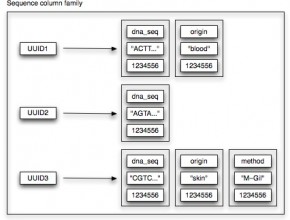
Big Data Genomics – How to efficiently store and retrieve mutation data
[information] This blog post is the first one in a series of articles that describe the use of NoSQL databases to efficiently store and retrieve mutation data. 1. Part one introduces the notion of mutation data and describes the conceptual use of the Cassandra NoSQL datastore. [/information] The only way to learn a new technology
Through this blog, we will try to keep you posted on our NoSQL escapades. Our goal is to provide you biweekly with a (technical) article that highlights a particular NoSQL aspect. Each technical article will be a self-contained piece of knowledge that can easily be digested and applied. Code samples will be made available through our github repository. Expect