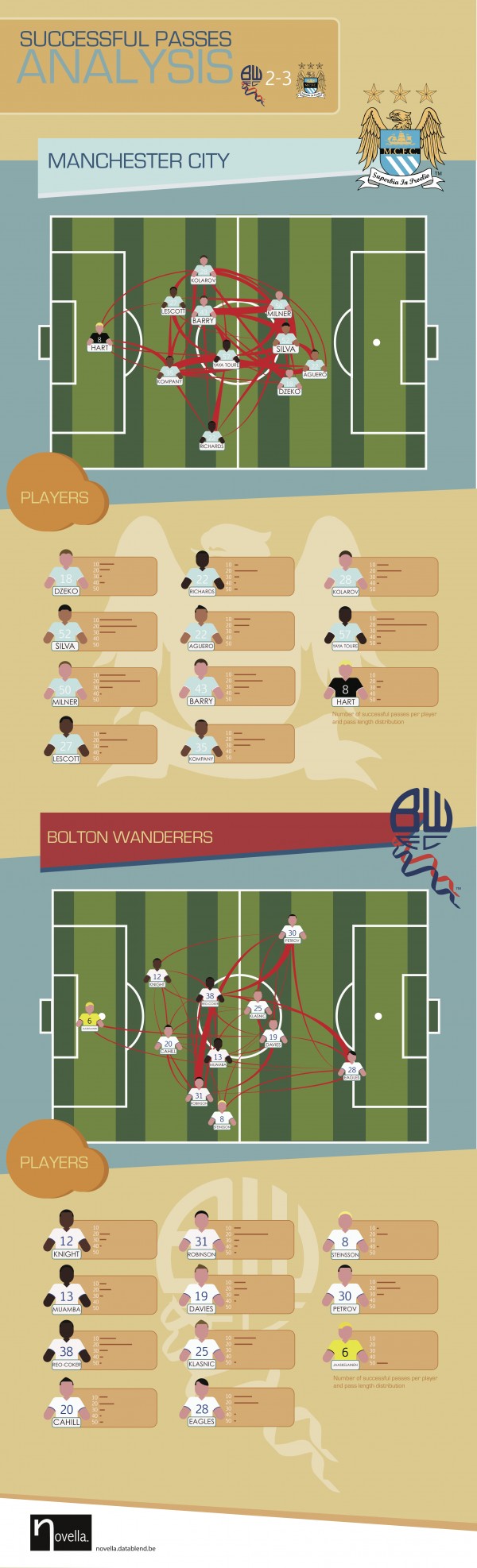
What makes Manchester City such a great team? The infographic below illustrates one of the teams most powerful characteristics: its successful passing capability. The visualisation is based upon the Opta dataset released in August 2011, containing the high detailed Bolton vs Manchester City match statistics. The data has been loaded in the neo4j graph databases
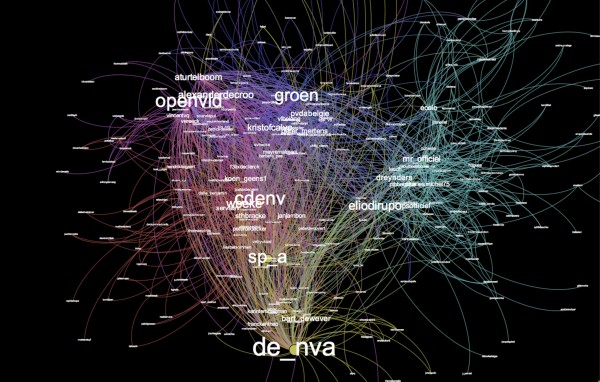
Last weekend, Engagor organised their hacktheelections hackaton. The Datablend team (Quentin, Stijn and Davy) was joined by Marc Broos, Tim Coene and Josbert van de Zande with one goal in mind: trying to visualise the (pre-arranged?) political coalition and, if possible, also predict the formation-period. Technically, we extracted over 160K tweets through the Engagor API.
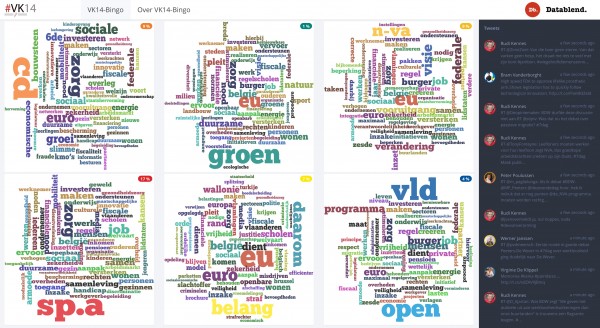
Wordt U ook overladen met informatie in verband met de komende verkiezingen? Bent U, net zoals zo vele andere burgers, op zoek naar een eenvoudig alternatief waarbij U in 1 oogopslag kunt zien waar elke partij voor staat? Zoek niet langer en maak gebruik van vk14-bingo.be. We hebben voor U de verschillende partijprogramma’s woord voor

Watch Davy Suvee present at GraphConnect London 2013 on the power of graph databases to analyse biological datasets. The Power of Graphs to Analyze Biological Data – Davy Suvee @ GraphConnect London 2013 from Neo Technology on Vimeo.
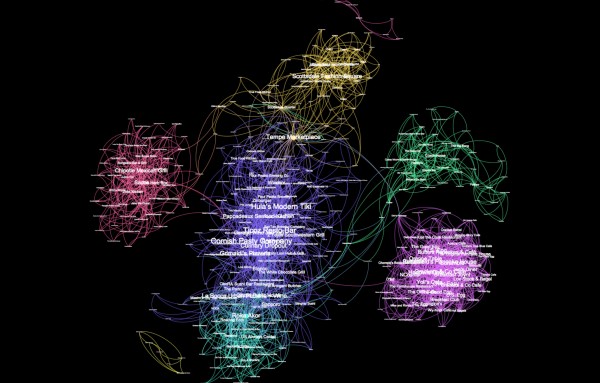
Recently, Yelp made available a sample dataset from the greater Phoenix metropolitan area including around 11.000 business, 8000 checkin-sets, 43.000 users and 230.000 user reviews. With the help of this data, data scientists can execute real-life experiments with various data mining/machine learning algorithms. In our case, we are interested in finding out whether it is possible

A few months ago, I discovered Vertica’s “Counting Triangles”-article through Prismatic. The blog post describes a number of benchmarks on counting triangles in large networks. A triangle is detected whenever a vertex has two adjacent vertices that are also adjacent to each other. Imagine your social network; if two of your friends are also friends
Today, Datablend announces Similr to be available for beta sign-up. Similr allows scientist (both from academics and enterprise) to quickly search for compounds that exhibit a particular chemical structure. It employs a wide range of fingerprinting algorithms, which combined, allow to identify matching compounds in millisecond time. Similr’s functionalities are available through a flexible and
Recently, I’ve started implementing a number of Redis-based solutions for a Datablend customer. Redis is frequently referred to as the Swiss Army Knife of NoSQL databases and rightfully deserves that title. At its core, it is an in-memory key-value datastore. Values that are assigned to keys can be ‘structured’ through the use of strings, hashes,
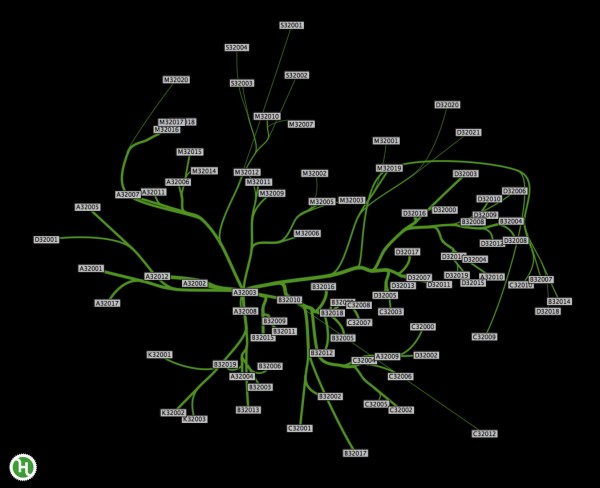
Last week, Hubway announced its Data Visualization Challenge. Hubway is a bike sharing system located in the Boston area: you simply pick up a bike at a particular station and drop it off at the closest station near your destination. For this challenge, Hubway released a CSV-file, containing over half a million rides. Each entry